InfLLM: Training-Free Long-Context Extrapolation for LLMs
InfLLM, introduced in May 2024 is a training-free, memory-based method that enables LLMs to process extremely long input sequences up to 1M tokens or beyond without any fine-tuning, while maintaining efficiency and preserving the model's original capabilities.
Why long contexts breaks LLMs
Most LLMs today are pre-trained on sequences limited to a few thousand tokens (e.g., 4K–32K, akin to a few pages of text). When encountering much longer inputs (tens or hundreds of thousands of tokens), to problem arise:
- Out-of-domain issues: The model hasn't been exposed to such lengths during pre-training, leading to degraded performance.
- Distraction and noise: Extended sequences often contain irrelevant information that dilutes attention and hinders capturing long-distance dependencies. The obvious fix is to retrain or fine-tune the model on longer sequences but it,
- Requires huge GPU resources.
- Needs scarce, high-quality long-sequence data.
- Risks degrading performance on short sequences.
Why Vanilla Attention Doesn't Scale
At the core of the Transformer lie attention mechanism, which scales quadratically with sequence length ($O(n²)$ complexity), quickly blowing up memory and compute cost. However efficient approximations exist:
- Sliding Window Attention: Tokens attend only to a fixed local window (e.g., recent tokens), reducing costs but discarding distant contexts.
- Sparse, kernelized, or state-space models: These optimize efficiency but still struggle with out-of-domain long contexts and may require retraining or architectural changes.
So the challenge isn’t just efficiency. It’s extrapolation: how to let a model pre-trained on short contexts handle arbitrarily long ones without retraining. InfLLM tackles this by extending sliding window attention with a retrieval-based memory that selectively reactivates distant but relevant information.
How InfLLM Works
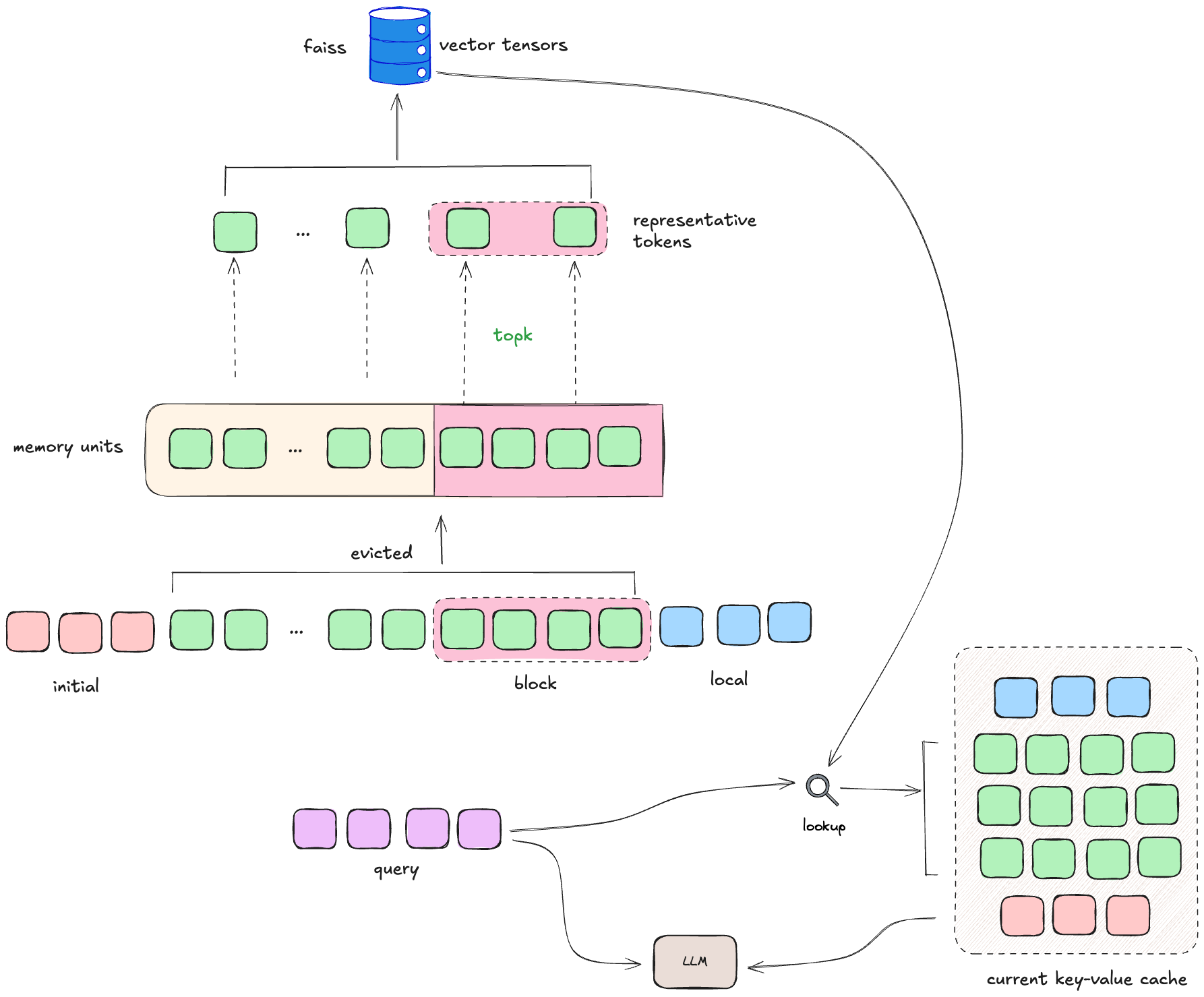
At a high level, InfLLM makes two key moves:
- It processes the input chunk by chunk instead of all at once.
- It offloads old tokens into an external memory, then brings back only the relevant parts when needed.
Past contexts
At each step, past key-value (KV) pairs from attention layers are categorized into:
- Initial tokens (I): The first few tokens (e.g., system prompts), always included as a fixed anchor.
- Local tokens (L): Recent tokens within the sliding window (e.g., 4K tokens), kept on GPU for quick access.
- Evicted tokens (E): Older tokens offloaded to external context memory (primarily on CPU to save GPU space). This structure allows InfLLM to keep the model focused locally while still having access to the entire history when needed.
Memory Units and Representative
Evicted tokens (E) are gropued into block-level memory units, with each unit containing a fixed number of contiguous tokens ($l_{bs}$=128). Within each block, only a few representative tokens are kept chosen based on their influence on local attention.
Representative Score
For the $m$-th token in a unit, the representative score is: $$r_m = \frac{1}{l_L} \sum_{j=1}^{l_L} q_{m+j} \cdot k_m$$ where,
- $q_{m+j}$: query bector of token in the local window of size $l_L$
- $k_m$: key vector of the $m$-th evicted token This averages the attention influence of the token on subsequent local queries, identifying semantically important tokens. Simply if a token strongly interacts with many local queries, it’s important enough to represent its block.
Selecting Representatives
For a block $B = { (k_j^B, v_j^B) }{j=1}^{l_{bs}}$:
- Select the top $r_k$ tokens (e.g., $r_k$=4) by highest $r_m$.
- Define representatives: $R(B) = { (k_{b_j}^B, v_{b_j}^B) }_{j=1}^{r_k}$. This way, each block is compressed to just a handful of semantically important tokens.
Memory Lookup: Retrieving Relevant Blocks
When a new chunk or query $X$ arrives, InfLLM decides which memory blocks are relevant. First calculate the similarity score between chunk and block $B$, that is: $$\text{sim}(X, B) = \sum_{i=1}^{l_X} \sum_{j=1}^{r_k} q_{i+l_P} \cdot k_{b_j}^B$$ where,
- $q_{i+l_P}$: query from the current chunk $X$
- $k_{b_j}^B$: representative key from block $B$
- $l_X$: Length of current chunk.
Blocks with high similarity are considered relevant. InfLLM selects the top $k_m$ blocks and loads their full KV pairs (not just the representatives) back into GPU memory.
Building the Current Cache
To compute the next step, InfLLM constructs a working cache: $$C = \text{Concat}(I, f(X, E), L)$$ where,
- $I$: initial tokens (always included)
- $f(X, E)$: retrieved top-$k_m$ memory units (full KV)
- $L$: local sliding-window tokens
This hybrid cache allows attention to span initial anchors, relevant distant memories, and recent context. It balances short-term focus and long-term recall.
Final Attention Computation
For current chunk $X$, attention is computed as: $$O = \text{Attn}[Q_X, \text{Concat}(C_k, K_X), \text{Concat}(C_v, V_X)]$$
- $Q_X,K_X,V_X$: Queries, keys, and values from $X$.
- $C_k,C_v$: Keys and values from the constructed cache.
- FlashAttention is used for efficient computation
Why InfLLM Matters
- Training-free: No fine-tuning or retraining required.
- Scalable: Works up to million-token contexts and beyond.
- Preserves performance: Maintains efficiency and doesn’t harm short-context capabilities.
- Retrieval-enhanced: Effectively equips an LLM with its own internal memory system.
InfLLM shows that with clever memory management, we can push LLMs far beyond their pretraining limits making ultra-long context reasoning practical without changing the model itself. In short, InfLLM turns sliding-window LLMs into memory-augmented models that can recall the right parts of million-token sequences all without retraining.
Challenges and Limitations of InfLLM
While InfLLM is a powerful approach, it’s not without trade-offs:
- Memory Management Overhead: Storing, compressing, and retrieving external memory units (often on CPU) introduces latency and engineering complexity.
- Approximation Errors: By compressing blocks into a handful of representatives, some fine-grained token-level information may be lost. This can occasionally hurt precision in tasks that rely on exact recall.
- Top-K Retrieval Bottleneck: Selecting the most relevant blocks requires computing similarity scores against memory. For extremely long histories, this can still be a computational bottleneck.
- Implementation Complexity: Compared to vanilla sliding window attention, InfLLM requires careful design of block partitioning, representative scoring, and retrieval mechanisms.
- Hardware Constraints: While it reduces GPU load, InfLLM often depends on large CPU RAM and fast CPU–GPU transfer, which may not always be available in deployment environments.
Towards InfLLM v2
Many of these limitations motivated the design of InfLLM v2. Instead of relying on token-level representative selection (which requires heavy memory access), v2 introduces semantic kernels with pooling and overlap, and a more efficient top-K retrieval strategy. This reduces memory bottlenecks and improves semantic coverage, while still avoiding retraining.