InfLLM v2: Fine-Grained Semantic Kernels for Efficient Long-Context Retrieval
InfLLM v2 builds upon the foundation of InfLLM but improves efficiency and semantic coverage by rethinking how relevance is computed between queries and memory blocks. Instead of relying on token-level representative selection, InfLLM v2 introduces semantic kernels overlapping, pooled representations of blocks that reduce memory access and better capture long-range semantics. It is a key proposed technique used in MiniCPM 4.
Motivation: Why v2?
InfLLM v1, while powerful, had bottlenecks:
- Token-level representative selection: Computing scores for every evicted token requires heavy memory access and can dominate runtime.
- Loss of semantic coverage: Choosing only a few top tokens from each block risks discarding useful context.
InfLLM v2 addresses these by introducing fine-grained semantic kernels and grouped block sharing.
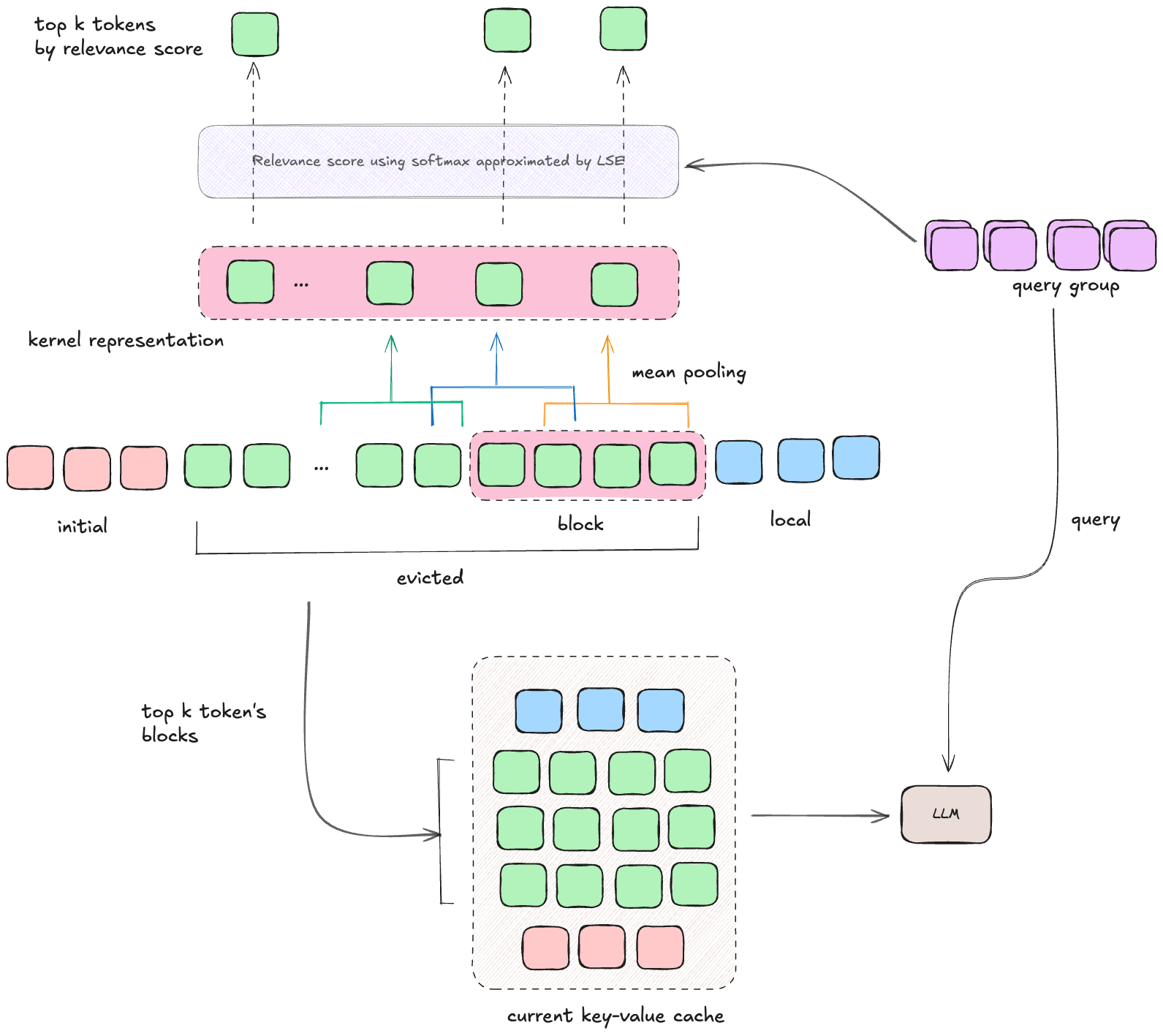
Semantic Kernels: Capturing Block Semantics
In v2, evicted tokens are still partitioned into coarse blocks (e.g., 128 tokens), but instead of picking a handful of representatives, each block is summarized using overlapping semantic kernels.
- Kernel construction:
- Each kernel is a span of $p$ tokens.
- Adjacent kernels overlap by a stride $s$ (like convolution with overlap).
- Example: If $p=32, s=16$, then kernels cover tokens [0–32], [16–48], [32–64], etc.
- Kernel representation: Each kernel $S_j$ is represented by the mean pooling of its key vectors: $$ \hat{S}j = \text{Mean}(K{js : js+p}) $$
- Kernel relevance: For a query $q_i$, relevance to a kernel is: $$
r_\text{kernel}(q_i, S_j) = \text{softmax}(q_i \cdot \hat{S}_j) $$ - Block relevance: A block $B$ may overlap with multiple kernels. Its relevance is the max kernel score among those overlapping kernels: $$ r_\text{block}(q_i, B) = \max_{S_j \cap B \neq \varnothing} r_\text{kernel}(q_i, S_j) $$
This avoids token-level scanning and still captures fine-grained semantics through overlapping spans.
Top-K Block Selection
Once relevance scores are computed, InfLLM v2:
- Aggregates scores across query tokens in a group.
- Selects the top-$k_m$ relevant blocks.
- Loads the full KV pairs of those blocks (not just pooled vectors) into GPU memory.
This ensures precision: kernels are used for scoring, but real attention is still computed on the original tokens.
Efficiency Optimizations
Grouped Query Sharing
Modern LLMs often use grouped query attention (GQA) where multiple queries share the same KV head.
- In v1, each query head computed its own relevance scores, increasing memory access.
- In v2, heads in the same group share the same top-k blocks, reducing redundant retrieval.
- Scores are averaged across the group before block selection.
Efficient LogSumExp (LSE) Approximation
A key challenge in InfLLM v2 lies in computing relevance scores for block selection. Recall that to normalize similarity scores, we need the softmax denominator, which involves computing a LogSumExp (LSE) across all kernels: $$\text{sim}(X, B) = \frac{\sum_{i,j} \exp(q_i \cdot k_j)}{\sum_{j’} \exp(q_i \cdot k_{j’})}$$ where $q_i$ are queries from the current chunk and $k_j$ are kernel representatives of block $B$. This differs from the final attention computation:
- In dense attention, FlashAttention can compute softmax in a single pass using its online LSE trick.
- But in block-level retrieval, relevance scoring requires ranking across blocks, which means we must compute or approximate the full denominator before picking Top-K. FlashAttention cannot be applied here. Instead of computing LSE over all fine-grained overlapping kernels (which are numerous), InfLLM v2 groups them into larger coarse kernels with stride $s_c \gg s$.
- Compute LSE only across these coarse kernels: $$\widetilde{\text{LSE}} = \log \sum_{j=1}^{N_c} \exp(q \cdot k_j^{\text{coarse}})$$
- Use $\widetilde{\text{LSE}}$ as an approximation to the true denominator.
- Normalize fine-kernel scores using this approximation.
This drastically reduces memory access and computation during block selection, while still preserving sufficient accuracy for relevance ranking.
Building the Cache
Once the top blocks are chosen, the working cache is constructed similarly to v1: $$ C = \text{Concat}(I, f(X, E), L) $$
- $I$: initial anchors (always included).
- $f(X,E)$: top-$k_m$ relevant blocks from memory (full KV).
- $L$: local window tokens.
Then standard attention is computed: $$ O = \text{Attn}[Q_X, \text{Concat}(C_k, K_X), \text{Concat}(C_v, V_X)] $$
Key Differences vs InfLLM v1
- Representative tokens (v1) → Semantic kernels (v2)
- Token-level scoring → Mean-pooled, overlapping spans
- Per-head top-k → Group-shared top-k
- Two-pass softmax (expensive) → Coarse-kernel LSE approximation (cheaper)
Challenges & Limitations
- Kernel pooling may blur fine details: Mean pooling cannot capture precise token-level signals.
- Overlapping increases memory footprint: More kernels than blocks → more scoring operations.
- Approximation trade-offs: Coarse-kernel LSE improves speed but may slightly reduce accuracy.
- Still retrieval-bound: Top-K selection remains a bottleneck at extreme context lengths.
Takeaway
InfLLM v2 refines the memory retrieval mechanism of InfLLM by using semantic kernels and efficient top-k block selection. This leads to:
- Better semantic coverage (overlap avoids missing info).
- Reduced memory access (no per-token scoring).
- Higher efficiency (coarse-kernel LSE and GQA sharing).
It’s not a free lunch, there are still trade-offs but InfLLM v2 pushes long-context extrapolation closer to practicality, without retraining.